背景
目前的告警通知采用grafana来通知dingding群,这只是grafana的一个功能,所以在灵活性上还是有很多缺陷的,不如专门做告警通知的alertmanager方便
grafana告警
优点:
- 可以发送趋势图,并且配置上来讲比较方便,直接在监控图里配置即可,比较简单
缺点:
- 不能创建一个告警模板应用到一批实例上,意味着我们要每个实例都去配置一下告警,非常麻烦。
- 不能分组,比如:一个集群的多台机器,都挂掉了,那我们可能一下分别收到5,6个告警,这样大量冗余消息,时间长了人可能会有疏忽。
- 告警恢复的消息,不能显示恢复的是哪个机器,只有一个ok和告警名,多个告警下来,具体是哪个恢复了我们也不知道。
alertmanger告警
优点:
- 可分组、静默、抑制(三大特性)来灵活控制告警规则发送到微信,钉钉,邮件,比如多个机器同个级别的告警可以合并成一个,避免冗余邮件。
- 告警恢复是完整显示信息的,恢复后我们可以知道是哪个机器恢复了,这直接完美替代了grafana的缺点。
缺点:
- 相对于grafana来讲,配置流程上要繁琐许多,并且很多字段也需要熟悉,dingding之类告警还需要安装第三方插件实现。维护起来确实有成本,但是一次配置好了,就可以慢慢享受它带来的优点了
核心概念
1. 分组
将类似性质的警报分类到单个通知中。这在较大的中断期间特别有用,因为许多系统同时发生故障,并且可能同时触发数百到数千个警报。这样解决了警报冗余
2. 抑制
抑制是一种概念,即在某些其他警报已触发时禁止显示某些警报的通知,比如server01触发了严重级别的警报,那警告(waring)级别的就没必要在通知了。抑制就是干这个用的
3. 静默
静默是一种在给定时间内简单地将警报静音的简单方法。静音是根据匹配器配置的,就像路由树一样。将检查传入警报是否与活动静默的所有相等或正则表达式匹配器匹配。如果这样做,则不会为该警报发送任何通知。静默是在警报管理器的 Web 界面中配置的。场景就比如:某一台机器设置了数据备份的定时任务,每天凌晨这段时间会占用大量CPU或内存,会超过阈值触发告警,那我们设置静默将其”静音“, 杜绝不必要的告警信息
整体实现思路
- 部署alertmanager
- 部署prometheus-webhook(实现钉钉告警的第三方插件)
- 在alertmanager.yml配置文件中配置邮箱服务器,模板路径,路由数,分组,接收人(定义接受的对象,如邮箱,微信,钉钉)
- 在prometheus-webhook配置文件config.yml中,来配置钉钉机器人的密钥与url(提前加好机器人),引用模板文件(就是alertmanager定义的模板)
- 配置Prometheus与Alertmanager通信
- 在Prometheus中创建告警规则
- 重启服务,测试
一. 安装Alertmanger
1.1 安装包下载
#alertmanager
地址1:https://prometheus.io/download/
地址2:https://github.com/prometheus/alertmanager/releases
#prometheus-webhook
https://github.com/timonwong/prometheus-webhook-dingtalk/releases
wget https://github.com/timonwong/prometheus-webhook-dingtalk/releases/download/v0.3.0/prometheus-webhook-dingtalk-0.3.0.linux-amd64.tar.gz1.2 两个安装包解压安装在/opt/下
tar -xvf alertmanager-0.28.0-rc.0.linux-amd64.tar.gz -C /usr/local/
mv alertmanager-0.28.0-rc.0.linux-amd64 alertmanager
tar -xvf prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz -C /usr/local/
mv prometheus-webhook-dingtalk-2.1.0.linux-amd64 prometheus-webhook1.3 两个服务service文件
alertmanager:
# cat /etc/systemd/system/alertmanager.service
[Unit]
Description=alertmanager
[Service]
ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.targetprometheus-webhook:
# cat /etc/systemd/system/prometheus-webhook.service
[Unit]
Description=Prometheus Dingding Webhook
[Service]
ExecStart=/usr/local/prometheus-webhook/prometheus-webhook-dingtalk --web.enable-ui --web.enable-lifecycle --config.file=/usr/local/prometheus-webhook/config.yml
ExecReload=/bin/kill -HUP $MAINPIDKillMode=process
Restart=on-failure
[Install]WantedBy=multi-user.target启动服务
systemctl start alertmanager
systemctl start prometheus-webhook.service二. 配置Prometheus
1. 配置Prometheus与Alertmanager通信
打开prometheus的配置文件 /usr/local/prometheus/prometheus.yml 进行修改
找到并修改为如下内容:
# Alertmanager configurationalerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
- "rules/*.yml"2. 创建规则目录
mkdir -pv /usr/local/prometheus/rules3. 配置规则
注意:这里列举两个常用的规则文件,其余根据实际情况自行修改(可以去prometheus的web页面上自己先查一遍,看表达式是否正确查出数据)
a. 主机存活告警文件,分组名为servers_survival:
groups:
- name: servers_survival
rules:
- alert: 节点存活 #告警规则名称
expr: up == 0
for: 1m #等待评估时间
labels: #自定义标签,定义一个level标签,标记这个告警规则警告级别: critical严重,warning警告
level: critical
annotations: #指定附加信息(邮件标题文本)
summary: "机器 {{ $labels.instance }} 挂了"
description: "服务器{{$labels.instance}} 挂了 (当前值: {{ $value }})"
- alert: 节点存活--华为云--生产ES服务器
expr: up{job="hw-nodes-prod-ES"} == 0
for: 1m
labels:
level: critical
annotations:
summary: "机器 {{ $labels.instance }} 挂了"
description: "{{$labels.instance}} 宕机(当前值: {{ $value }})"b. 主机状态告警文件,分组名为servers_status:
root@rancher2x.hw:/opt/prometheus/rules# cat servers_status.yml
groups:- name: servers_status
rules:
- alert: CPU负载1分钟告警
expr: node_load1{job!~"(nodes-dev-GPU|hw-nodes-test-server|hw-nodes-prod-ES|hw-nodes-prod-MQ)"} / count (count (node_cpu_seconds_total{job!~"(nodes-dev-GPU|hw-nodes-test-server|hw-nodes-prod-ES|hw-nodes-prod-MQ)"}) without (mode)) by (instance, job) > 2.5
for: 1m
labels:
level: warning
annotations:
summary: "{{ $labels.instance }} CPU负载告警 "
description: "{{$labels.instance}} 1分钟CPU负载(当前值: {{ $value }})"
- alert: CPU使用率告警
expr: 1 - avg(irate(node_cpu_seconds_total{mode="idle",job!~"(IDC-GPU|hw-nodes-prod-ES|nodes-test-GPU|nodes-dev-GPU)"}[30m])) by (instance) > 0.85
for: 1m
labels:
level: warning
annotations:
summary: "{{ $labels.instance }} CPU使用率告警 "
description: "{{$labels.instance}} CPU使用率超过85%(当前值: {{ $value }} )"
- alert: CPU使用率告警
expr: 1 - avg(irate(node_cpu_seconds_total{mode="idle",job=~"(IDC-GPU|hw-nodes-prod-ES)"}[30m])) by (instance) > 0.9
for: 1m
labels:
level: warning
annotations:
summary: "{{ $labels.instance }} CPU负载告警 "
description: "{{$labels.instance}} CPU使用率超过90%(当前值: {{ $value }})"
- alert: 内存使用率告警
expr: (1-node_memory_MemAvailable_bytes{job!="IDC-GPU"} / node_memory_MemTotal_bytes{job!="IDC-GPU"}) * 100 > 90
labels:
level: critical
annotations:
summary: "{{ $labels.instance }} 可用内存不足告警"
description: "{{$labels.instance}} 内存使用率已达90% (当前值: {{ $value }})"
- alert: 磁盘使用率告警
expr: 100 - (node_filesystem_avail_bytes{fstype=~"ext4|xfs", mountpoint !~ "/var/lib/[kubelet|rancher].*" } / node_filesystem_size_bytes{fstype=~"ext4|xfs", mountpoint !~ "/var/lib/[kubelet|rancher].*"}) * 100 > 85
labels:
level: warning
annotations:
summary: "{{ $labels.instance }} 磁盘使用率告警"
description: "{{$labels.instance}} 磁盘使用率已超过85% (当前值: {{ $value }})"4. 热加载prometheus配置
curl -X POST http://localhost:9090/-/reload去web上查看确认rules是否被prometheus加载
三. 配置Alertmanger
上面配置了prometheus与alertmanager的通信,接下来我们配下alertmanager来实现发送告警信息给我们
这里我们主要以钉钉告警为例子
- 钉钉上添加一个钉钉机器人,设置好名字,群组,选择加签,确定。
2. 修改prometheus-webook配置文件绑定申请的机器人
我只绑定了一个webhook所以只要配置到webhook1
root@rancher2x.hw:/opt/prometheus-webhook# cat config.yml
## Customizable templates path
templates:
## - templates/alertmanager-dingtalk.tmpl
- /usr/local/prometheus-webhook/template.tmpl # 配置告警模板的所在位置
#default_message:
# title: '{{ template "legacy.title" . }}'
# text: '{{ template "legacy.content" . }}'
## Targets, previously was known as "profiles"
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxx # 配置机器人的webhook_url
# secret for signature
secret: SEC65342be21ab54b730da9347be9307b7831bd65adf1c99406fedc786f62fecb98 # 配置加签(申请的时候那串数字)
message:
text: '{{ template "default.tmpl" . }}'3. 告警模板文件
[root@prod prometheus-webhook]# cat template.tmpl
{{ define "default.tmpl" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
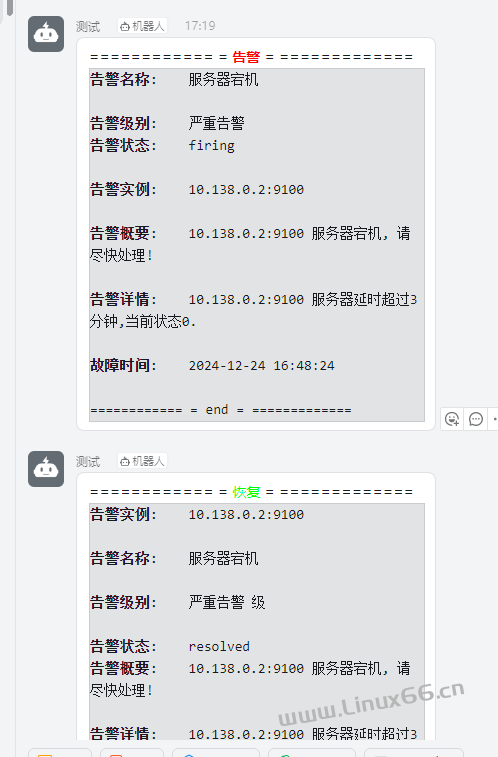
============ = **<font color='#FF0000'>告警</font>** = =============
**告警名称:** {{ $alert.Labels.alertname }}
**告警级别:** {{ $alert.Labels.severity }}
**告警状态:** {{ .Status }}
**告警实例:** {{ $alert.Labels.instance }} {{ $alert.Labels.device }}
**告警概要:** {{ .Annotations.summary }}
**告警详情:** {{ $alert.Annotations.message }}{{ $alert.Annotations.description}}
**故障时间:** {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
============ = end = =============
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
============ = <font color='#00FF00'>恢复</font> = =============
**告警实例:** {{ .Labels.instance }}
**告警名称:** {{ .Labels.alertname }}
**告警级别:** {{ $alert.Labels.severity }} 级
**告警状态:** {{ .Status }}
**告警概要:** {{ $alert.Annotations.summary }}
**告警详情:** {{ $alert.Annotations.message }}{{ $alert.Annotations.description}}
**故障时间:** {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
**恢复时间:** {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
============ = **end** = =============
{{- end }}
{{- end }}
{{- end }}
4. 修改alertmanager配置文件为如下内容
注:这里也加上了邮件相关的配置
[root@prod local]# cat alertmanager/alertmanager.yml
route:
group_by: ['dingding']
group_wait: 30s # 分组内第一个告警等待时间,10s内如有第二个告警会合并一个告警
group_interval: 1m # 发送新告警间隔时间
repeat_interval: 30s #重复告警间隔发送时间,如果没处理过多久再次发送一次
receiver: 'dingding.webhook1'
routes:
- receiver: 'dingding.webhook1'
match_re:
alertname: ".*"
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
- name: 'dingding.webhook1'
webhook_configs:
- url: 'http://localhost:8060/dingtalk/webhook1/send' # 填写prometheus-webhook的webhook1 url
send_resolved: true # 在恢复后是否发送恢复消息给接收人
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
5. 重启服务
systemctl restart prometheus-webhook.service
systemctl restart alertmanager.service四. 测试
- 我们可以通过故意调整阈值 或者 停掉告警检测中主机上的node_exporter探针来测试一下
root@rs02.test.hw:~# systemctl stop node_exporter.service
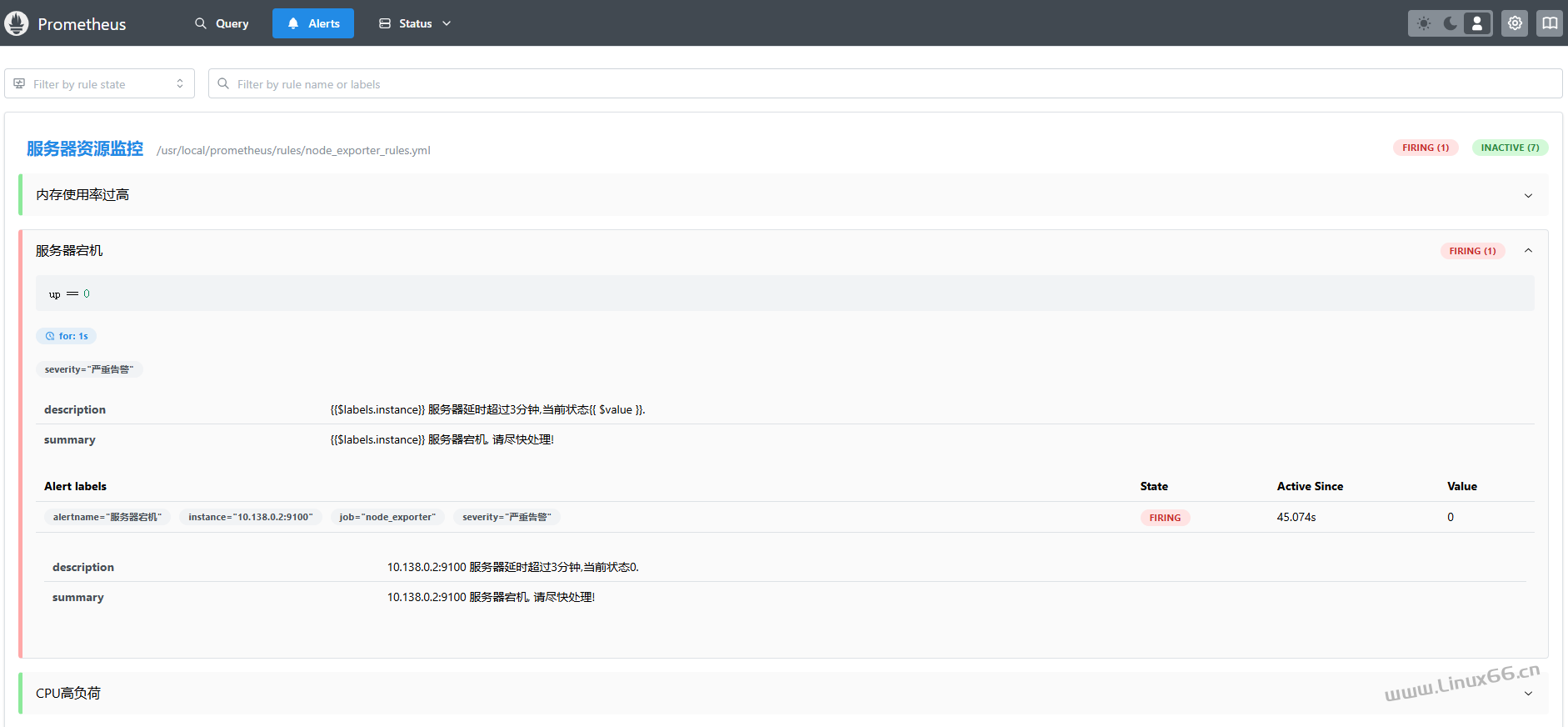
2.prometheus上可以看到已经触发了告警规则阈值
3.此时钉钉群里收到了告警邮件 (这里图示是恢复探针后,告警和恢复消息一起展示)