
2024年12月11日,OpenAI出现了全球性的严重宕机事件,这次事件导致OpenAI的所有服务包括ChatGPT、API和 Sora等都受到了严重影响,甚至出现无法访问的情况。关于此次事件的起因,目前官方已经出了故障报告,详见:https://status.openai.com/incidents/ctrsv3lwd797。在本文中,我将带大家深入了解OpenAI的此次故障事件,在别人的错误中得到经验教训。这次的事件过程的主要时间线如下:
- 2024年12月11日下午3:17 PST (太平洋标准时间),OpenAI的所有服务开始出现不可用现象。随着时间的推移,问题逐渐加重,导致客户在多个时段无法访问API、ChatGPT及Sora。
- 下午3:53 PST,工程师发现API调用返回错误,用户无法登录OpenAI平台,问题迅速扩展至多个服务。
- 随着时间的推移,OpenAI的工程团队最终确定了故障原因,并启动了应急响应。到了下午7:38 PST,所有服务才得以完全恢复。
从引发事故到最终恢复,时间超过了4个小时,对于ChatGPT和Sora这种全球性业务而言,影响可谓巨大。
本次故障的根本原因与OpenAI新部署的一项监控服务有关,该服务用于收集Kubernetes控制平面的指标。但由于配置问题,导致集群中的每个节点都向Kubernetes API发起了大量的请求。这些请求的急剧增加超出了Kubernetes控制平面的处理能力,最终导致控制平面崩溃。
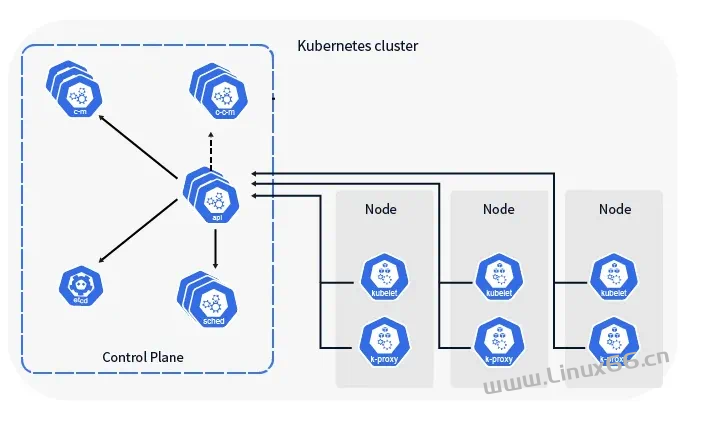
Kubernetes的控制平面是整个集群管理的核心,负责调度、监控和管理集群的状态。尽管Kubernetes的数据平面(即各个Node节点和Pod)可以在控制平面出现问题时继续运行,但在这次事件中,存在一个关键的依赖问题——CoreDNS。
CoreDNS是Kubernetes中负责服务发现和DNS解析的核心组件,它运行在控制平面内,用于为Pod提供DNS解析服务。在控制平面崩溃后,CoreDNS无法提供有效的DNS解析服务,导致Pod内部的服务无法通过DNS解析找到其他服务的地址。
这一问题最终引发了连锁反应,直接导致大量服务无法使用。
为了解决Kubernetes控制平面过载的问题,OpenAI的工程师团队采取了多种策略,包括:
- 缩小集群规模:通过减少Kubernetes API的负载,缓解了控制平面压力。
- 阻止访问Kubernetes管理API:避免了新的高负载请求,使得API服务器有时间恢复。
- 扩展Kubernetes API服务器的资源:增加了资源来处理待处理的请求,直到问题得以解决。
通过这些措施,OpenAI最终成功恢复了服务,并逐步将流量引导到健康的集群中。在这次事件中,可以看到即使是如 OpenAI这种万亿级别的企业,在核心基础设施上依然存在显著的短板。作为Kubernetes集群的核心组成部分,控制平面居然没有足够的冗余节点,听起来有点不可思议。
我不想评价草台班子之类的话,毕竟作为这种级别的企业,我相信他们一定配备了非常优秀的工程师团队。但有些技术问题的发生,很多时候并不在工程师的可控范围。毕竟现在不少企业中都流行着“降本增效”,而基础架构团队在这种环境下往往面临着如何最大化降低成本的压力,甚至会成为考核的关键指标。这种成本驱动的决策方式,容易导致团队在执行过程中更加功利化,过度追求短期的成本节约,而忽视了基础设施可能带来的长远风险。而基础设施作为企业运营的根基,任何不恰当地削减和简化都有可能带来灾难性的后果。今年,已有几起大厂的严重事故,正是因为基础设施问题而引发的。对于这类业务严重依赖互联网的企业而言,这种影响直接关系到其核心业务的稳定性和可持续性。因此,我建议作为行业头部的各家公司还是要多关注下基础设施的建设和投入,该花的钱还是得花,不是所有领域都适合通过压缩成本来提升效率。特别是在技术和基础设施层面,过度的成本削减可能导致难以预见的风险。
