
我们在做性能测试的时候,往往会发现我们的pod服务,频繁重启,通过kubectl get pods 命令,我们来逐步定位问题
现象:running的pod,短时间内重启次数太多

定位问题方法:查看pod日志
kubectl get event #查看当前环境一个小时内的日志
kubectl describe pod pod_name #查看当前pod的日志
kubectl logs -f pod_name --previous #查看重启之前的那一次pod的日志,从那一刻开始计算
###############
一般用以上的三个命令就行
本次使用以下命令,解决了问题
kubectl describe pod pod_name问题原因:OOM,pod被kill掉,重启了(内存不够用)
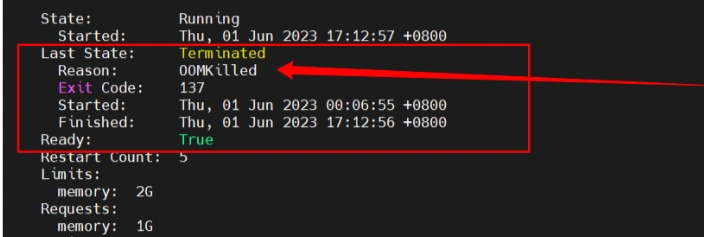
查看该服务的deployment.yaml文件

发现我们deployment.yaml对服务的内存使用,做了限制
解决方法:将limit的memory数值提高,然后delete -f yaml,再apply -f yaml
至此我们成功解决问题,并发现问题发生的根本原因
链接:https://bbs.huaweicloud.com/blogs/413818
(版权归华为云社区原作者所有,侵删)
声明:
本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。