
夜莺监控 Nightingale 发布了 v7.7 版本,这是 v7 系列的最后一个版本,保守主义者可以放心上车了,v7.7 主要是做了一些小修小改,增强了使用体验,下周开始,启动 v8 版本的开发。v8 版本会更让人激动,会重构通知逻辑,支持 ElasticSearch、ClickHouse 等数据源的告警,另外机器告警策略也会和业务组联动,更多功能敬请期待。
v7.7 主要变更
- feat: 告警规则数据源筛选,支持反选和模糊匹配
- feat: 告警规则查询条件支持设置 “单位”
- feat: 告警规则支持 “覆盖全局回调” 设置
- feat: 告警规则 Prometheus 源数据源预览添加 Step 设置
- refactor: 仪表盘详情页添加返回仪表盘列表链接
- refactor: tdengine 数据源,兼容 v2 版本
- fix: 修复仪表盘 Elasticsearch 源 legend 模板不支持变量名包含字符 “.” 的问题
- fix: edge 模块,机器失联告警,标签丢失问题
- doc: 告警规则告警级别名称优化
- doc: 增加 Doris 仪表盘和告警模板
v7 大版本重要变更如下
- 全站暗黑主题
- 新增指标视图,内置上百个 promql,无需手写 promql 即可方便地查看监控数据
- 新增模版中心,支持创建和修改模板,模版可以在一个地方集中维护和查看
- 机器支持了绑定到多个业务组,机器混部的场景,管理机器更加方便了
- 优化边缘机房机器失联告警的实现逻辑,真正做到边缘机房告警自闭环
- 通知时支持配置过滤标签,避免告警事件中一堆不重要的标签
- 全局回调地址页面展示优化,增加详尽的文档提示信息
- 支持通过回调地址直接发送告警信息到钉钉、飞书、企微等
- 内置集成故障自愈能力,不需要再单独部署 ibex 模块
- 仪表盘变量支持和本业务组的机器联动,不同业务组组下的仪表盘只展示本业务组内的机器
- 机器列表和指标视图打通,可以选择多台机器直接看图,无需任何提前配置
- 告警规则,支持配置恢复时的 Promql,告警恢复通知也可以带上恢复时的值了
- 支持通过回调地址直接发送告警信息到钉钉、飞书、企微等
- 支持集成仪表盘,可以将 grafana 的仪表盘集成到夜莺中
升级方法
v7 小版本升级直接替换二进制和 integrations 目录即可,如果用的镜像,就要拉取最新镜像了。v7.7 涉及 edge 模块变更,所以如果你用了 n9e-edge,记得 n9e-edge 也要升级。
近期数据库变更统一放 这里 了,正常来讲如果你在夜莺里用的 DB 账号可以创建修改表结构就不用操心了,如果你的 DB 账号没法修改表结构,可以根据这个 migrate.sql 文件手动执行一下。
夜莺项目介绍
夜莺监控最早是 2020 年由滴滴开源,后来捐赠给中国计算机学会,托管在学会开源发展委员会运作。夜莺监控侧重点在监控,可以支持不同的数据源,用一套 UI 管理多个数据源的告警规则,支持多种通知方式。当然,夜莺也内置了可视化能力,内置了各类组件的告警规则和仪表盘模板。
夜莺 v7.7 版本安装测试
这里我使用 Docker 来安装测试,从 https://flashcat.cloud/download/nightingale/ 下载 7.7 版本的发布包,解压后,进入目录 docker/compose-bridge,执行以下命令:
docker compose up -d注意:如果你的机器上之前拉取过夜莺的镜像,需要再重新 pull 一下,因为镜像有更新。待 docker compose 把所有容器拉起来,使用浏览器访问该机器的 17000 端口即可看到夜莺的 UI,使用
root/root.2020登录,登录之后第一件事情,记得修改密码。
由于夜莺是对接多种数据源的模式,所以要把想要监控的数据源接入进来。使用 Docker compose 启动的话,默认会启动一个 VictoriaMetrics,所以这里我们先接入此数据源,菜单入口在 集成中心 - 数据源:
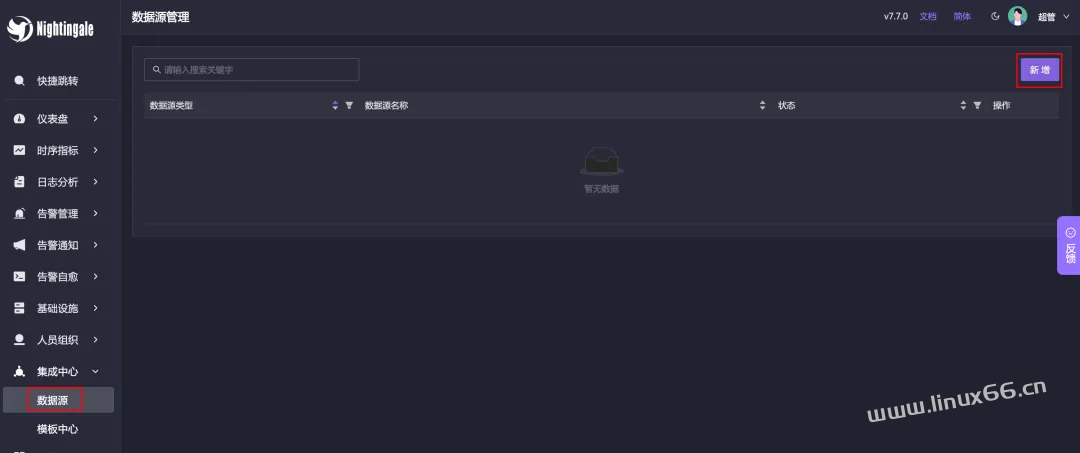
点击【新增】按钮,选择 Prometheus Like 数据源,所有和 Prometheus 兼容的数据源都选择 Prometheus Like 类型,然后填写数据源的名称和地址即可,其他的配置项可以留待以后再研究:
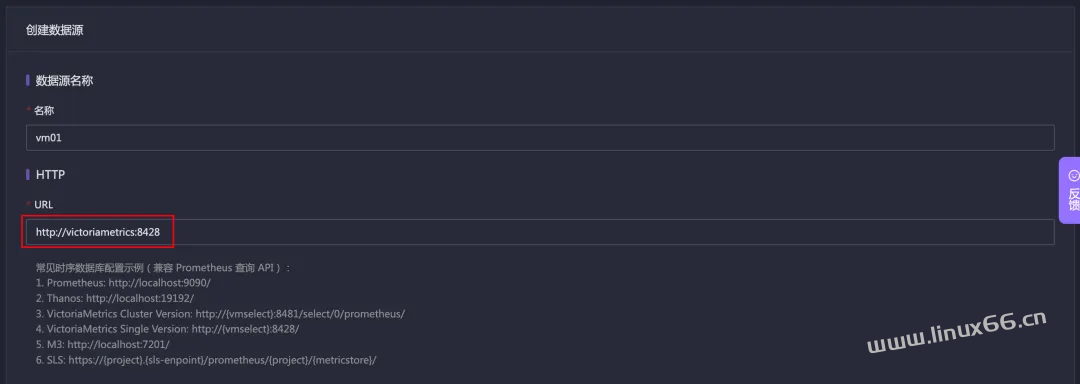
注意这里的 VictoriaMetrics 的 URL,写的是 http://victoriametrics:8428,因为是在容器里的嘛。完事就可以查看数据了。我们先到即时查询页面看看数据能否查到:
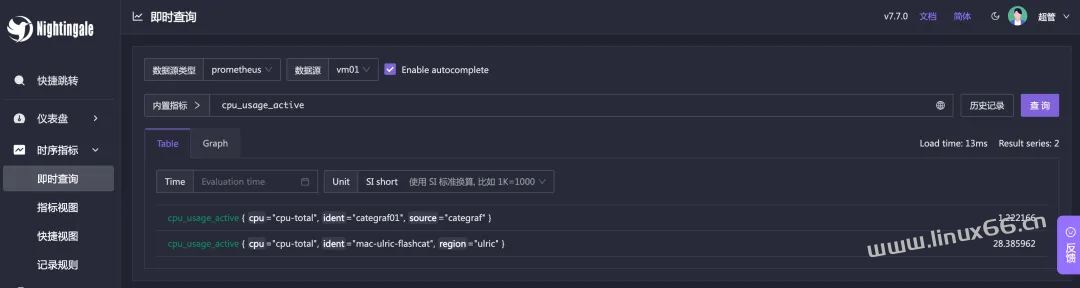
看起来没问题的。
默认情况下,Docker compose 会拉起一个 categraf 的镜像作为采集器,所以可以采集到一些监控数据。你的环境的话应该只会看到一台机器的数据,我的环境可以看到两条是因为我还部署了另一个 categraf。到机器列表页面可以很明显看到:
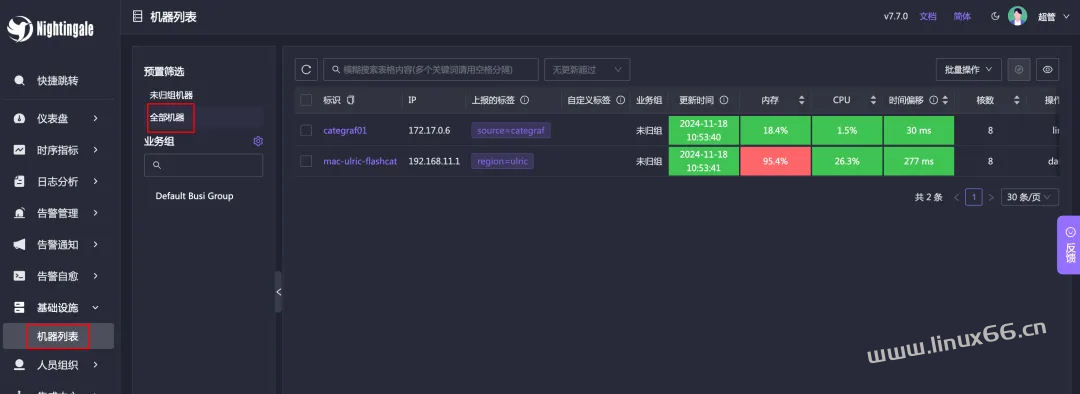
接下来我们导入一个仪表盘看看,进入仪表盘列表页面,选择左侧的某个业务组(我这里选择默认的 Default Busi Group),点击右上角的【导入】按钮:
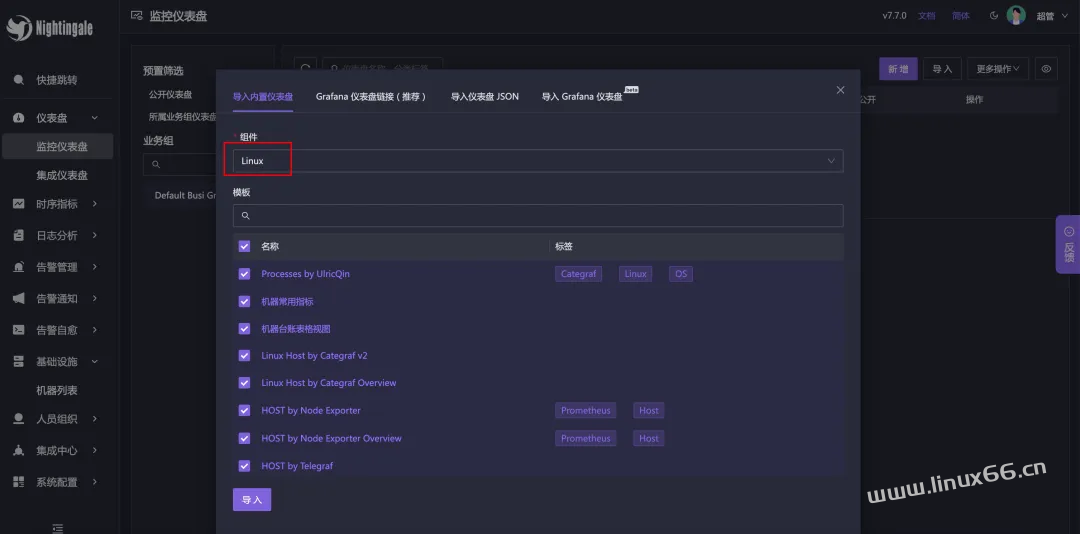
我这里选择导入机器相关的仪表盘,所以选择 Linux 类别,然后把所有仪表盘都导入进来,有些仪表盘不适用 Categraf 采集器,没关系,挨个点点看看哪个好使就用哪个。
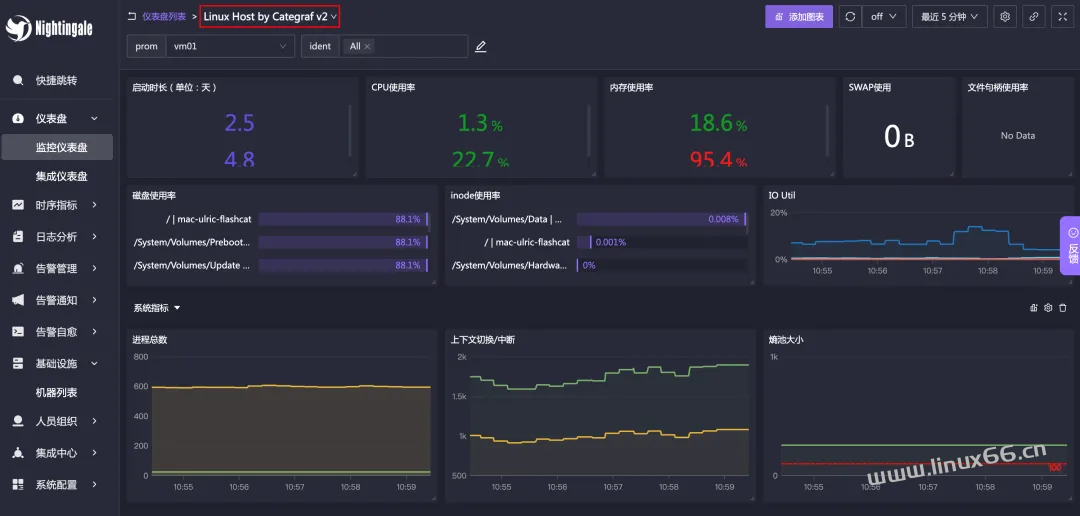
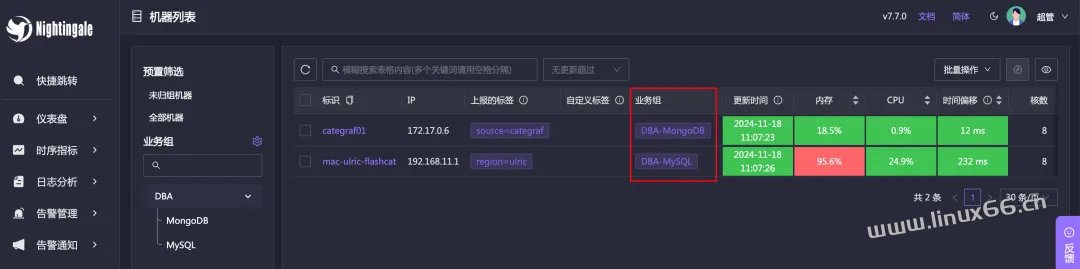
比较齐全的是 Linux Host by Categraf v2 这个仪表盘。通过这个仪表盘你可以看到时序库中的所有机器。有些人会说,我只想看到自己业务组下的机器怎么搞?比如我这个环境里有两个机器,我把这两个机器分别挂到不同的业务组下:
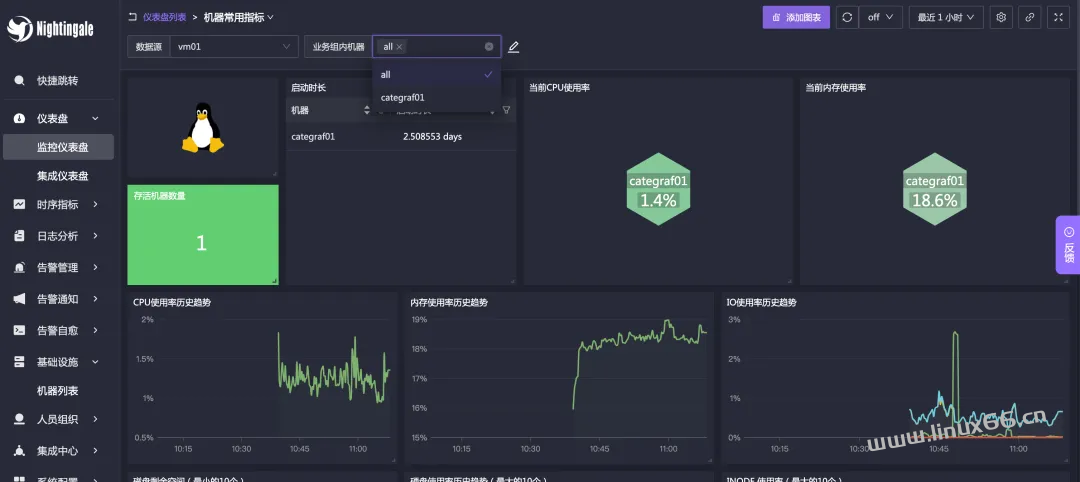
之后,我们重新进入仪表盘页面,在不同业务组下分别打开:“机器常用指标”这个仪表盘,这个仪表盘只能看到当前业务组下的机器:
OK,我们再试试导入一批告警规则,进入告警规则页面,点击右上角的【导入】按钮:
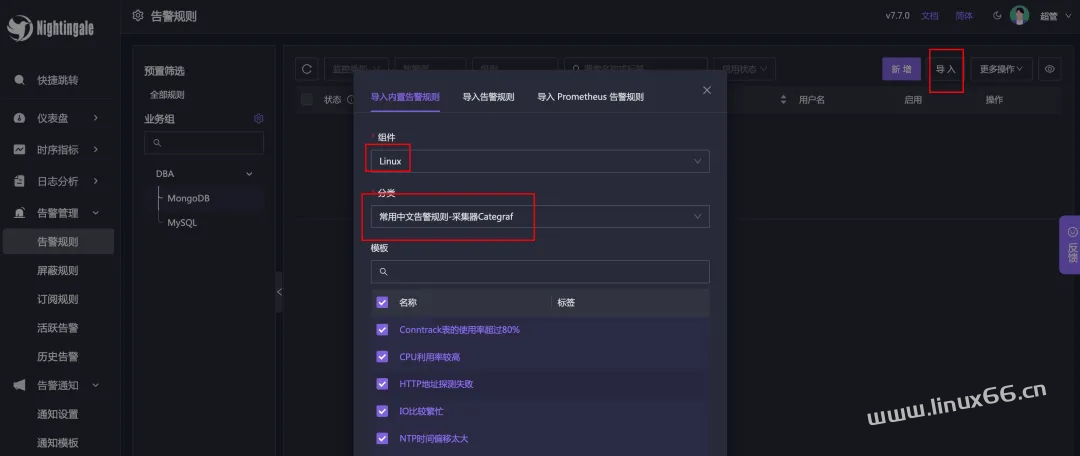
导入 Linux 类别下的常用告警规则。导入的时候要选择生效到哪些数据源,我这里只有一个数据源,就选择所有数据源了。可以先不启用,等以后有需要再启用。
最后我们搞一个钉钉机器人:
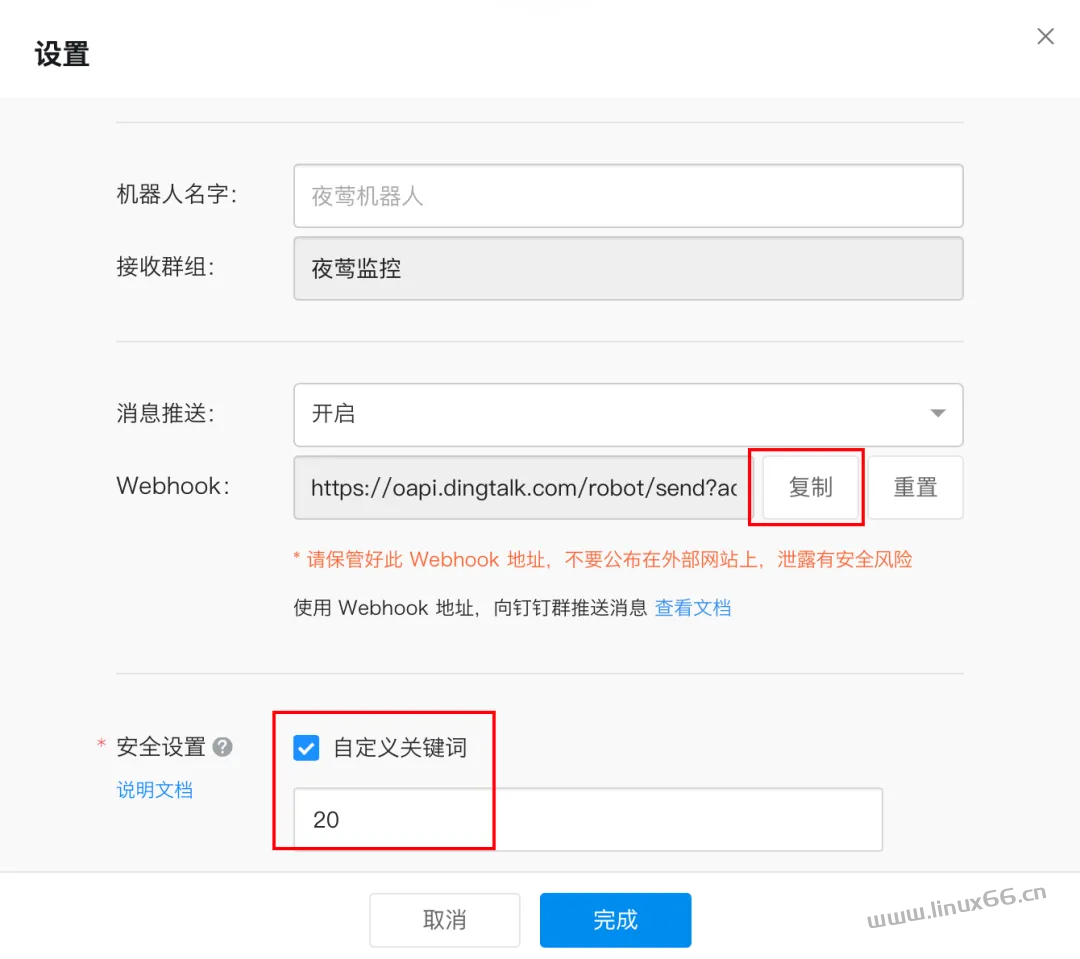
使用关键字作为认证机制,关键字写 20,因为告警消息中一定会有时间的,所以用 20 一定可以验证通过。批量选中刚才导入的告警规则,更新告警规则:
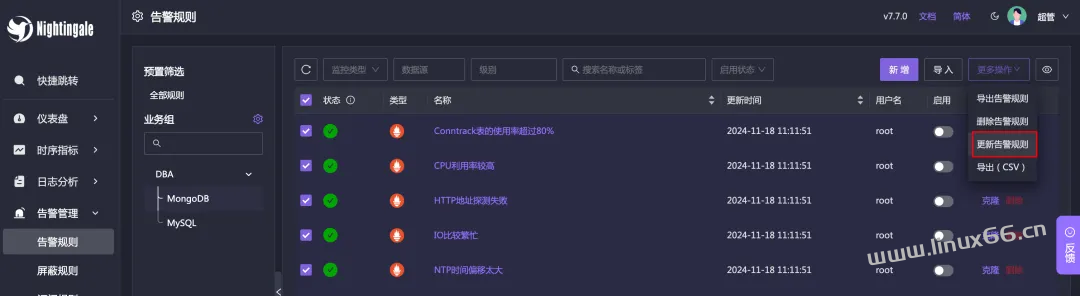
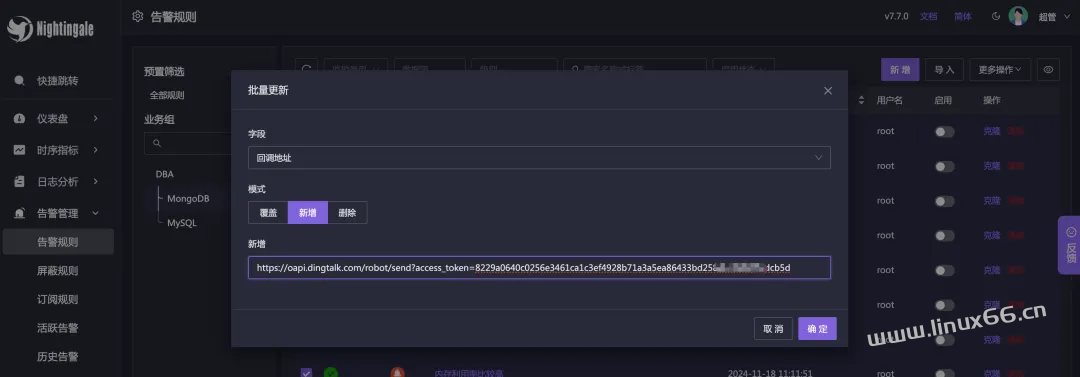
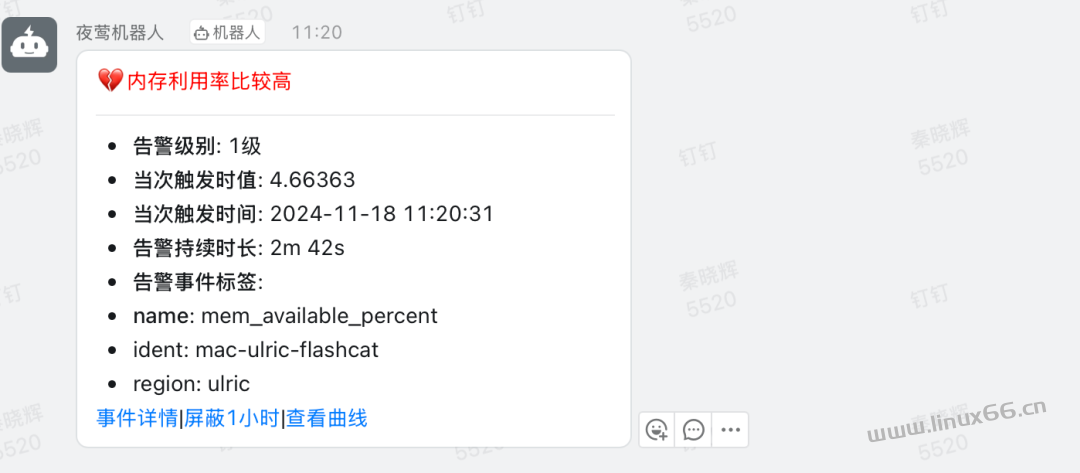
批量更新所有告警规则的回调地址,塞入钉钉机器人的 webhook 地址。这样之后,后面这些告警规则如果触发了告警,就会发送到钉钉机器人了。
最后,批量更新告警规则,启用:
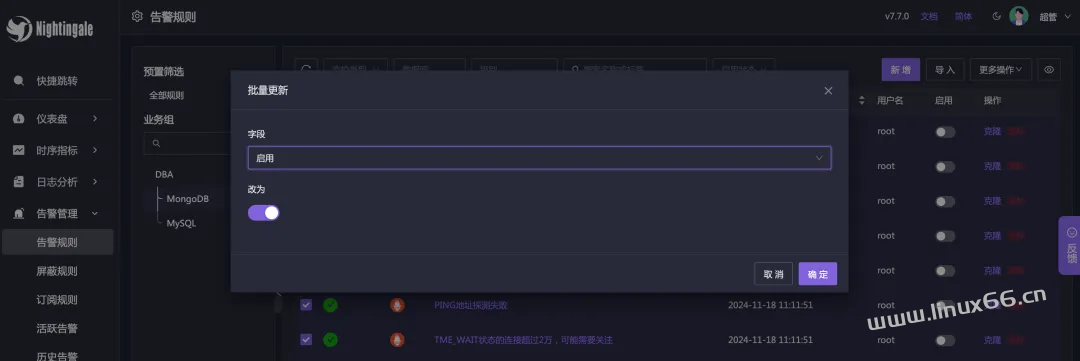
之后如果有哪个规则触发了,就会发告警到钉钉了,当然,你为了快速体验,也可以手工修改某个告警规则的阈值,让它尽快触发。就可以看到效果了。
更多功能探索,请参考 夜莺官方文档。文中链接如果丢失,请访问原文,原文地址:https://flashcat.cloud/blog/nightingale-release-v7final/
